Hacking on Scientific Text at Scale
status: in-review
I work on new interfaces to scientific knowledge. In the last couple of months, I've seen developments that drastically lower the entry barrier for working with high level concepts from scientific text.
Knowledge applications that understand the ever higher semantics of physical and life science texts can increasingly be built without years of machine learning experience.
High level sophisticated language tools are now hackable.
Of course, this sort of progress is a given, so to go beyond truisms like "Machine Learning is moving fast", I claim that:
In the last two years, practical NLP tooling for scientific literature application - recently coined #sciNLP* - has progressed three times above baseline of other ML domains like vision, reinforcement learning and generic NLP.
I arbitrarily group these directions of improvement into Models, Patterns and Data, although these concepts are constantly dancing a 3-way-semantically-drifting-tango**
Models: Strong Gains in "Low Level" Language Processing and Pipeline Modularity
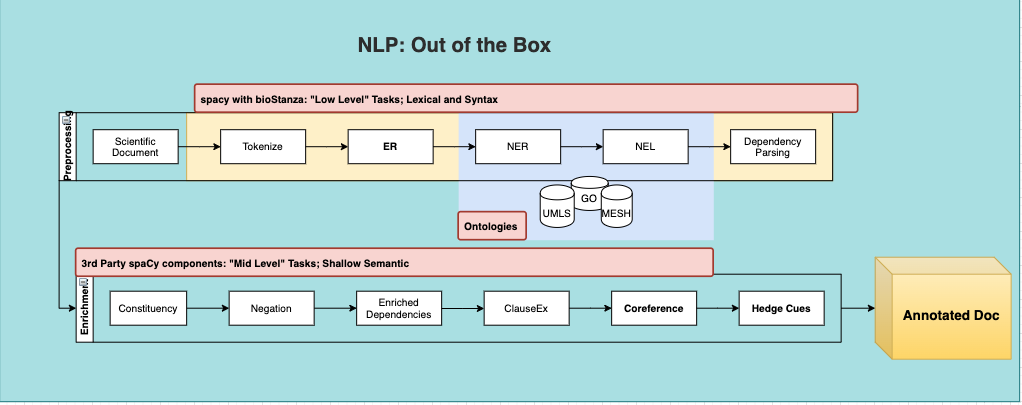
Stronger Fundament: Foundational (upstream) tasks in the scientific NLP pipeline, like tokenization, syntactic parsing, Named Entity Recognition [NER] and entity linking (matching an entity with a concept inside an ontology) have seen big -often double digit F1 or accuracy- gains in domain specific benchmarks.
Out-of-the-Box Access to Named Entities and Ontologies: SciSpacy and recently BioStanza and others make it much easier to work with biomedical entities in text. This goes beyond the biomedical domain and can be adapted for metallurgy, agrochemical, material science, biophysics, etc.

Modular Language Legos: Many pre-trained models for specific tasks like negation detection, clause extraction or constituency parsing are now just simple spaCy pipeline modules. SciSpacy and BioStanza integrate nicely with spaCy, which by itself has one of the best developer experiences of any open source tool.
Patterns: Finding Rules without Linguists
In practice, natural language applications are still largely built with hand-coded rules, heuristics and pattern matching algorithms and not some end-to-end neural network. That's because that is still the best bet for getting high-precision, interpretable, debuggable results.
A rule based system works mostly off of surface forms. A pattern, like in the image below, can catch one surface form of an idea.
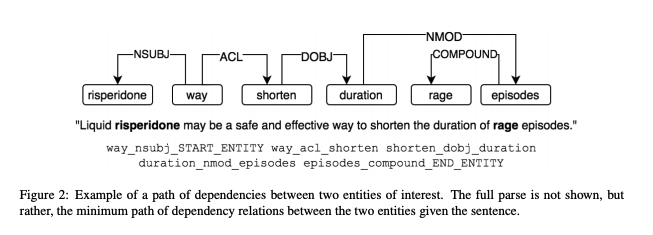
But, as it turns out, there's thousand, often tens of thousands of surface forms that can correspond to an idea. That's why rule-based systems are said to be low on recall, or quantity of results.
On the other hand, a trained model can learn a fuzzy notion of similarity, a distributional semantic. In its high-dimensional distributional space, sentences can happen to be close together for arbitrary reasons, which leads to noisy results.
That's why it's still important to build reliable linguistic patterns, most often based on constituency, dependency, keywords or simple phrase matching.
Still, I predict that neural networks can do that job as well in about three years, at least for relation extraction.
But until then, an approach I like is Spike. Scientists can use it as an advanced search tool, but there's another use: quickly, iteratively finding new syntax-informed query patterns for relation extraction.
A search system with full corpus fast trial and error like Spike was not possible until a recent 150.000x improvement in syntax-based graph traversal. 150.000 times...

With that interface, we can find patterns with much less linguistic finesse: just type a query, get a quick view of what it returns, correct for edge cases and filter out bad hits. Rinse and repeat.
Then combine syntax based search with neural search and query-by-example and have the best of both worlds.
Besides having a sanity check for syntax patterns, I feel query-by-example is an idea we should port to consumer knowledge tools. We could also use query-by-inverted-example to find contradicting sentences in a corpus for example.
Caveat: All these dependency (syntax) based strategies and many of rule based algorithms work downstream from dependency parsing (labels in the syntax tree), which is not as reliable as you might hope***.
This includes efforts to feed syntax trees into neural networks (1, 2) and hierarchical clustering and annotating dependency paths into themes****.
If the dependency parsing is inaccurate, then things fall through the cracks.
Data: Bootstrapping Small but Good-Enough Datasets
Besides out-of-box, extensible annotation tooling like prodi.gy, there is under-the-radar ideas like Question-Answering Semantic Role Labeling [QA-SRL] that can improve crowdsourcing for complex annotation tasks.
You can think of QA-SRL as a language model decomposing a hard annotation task into many simple questions.
This means you can increasingly hire layman annotators, ie. your unemployed extended family, and cut cost of labeled data by 5-10 times compared to expert annotators:
Exploiting the open nature of the QA-SRL schema, our nonexpert annotators produce rich argument sets with many valuable implicit arguments.
[...] Our workers’ annotation quality, and particularly its coverage, are on par with expert annotation
From Controlled Crowdsourcing for High-Quality QA-SRL Annotation
May 2020

And QA-SRL mixes well with Almost Semantic Role Labeling, which is the idea that you can simplify most NLP tasks into a span prediction task. As Mark Neumann noted:
"The overall idea is to use natural language questions (mostly from templates) to extract argument spans for particular roles. This abstracts away the linguistic knowledge required to annotate this data, but also, from a more practical point of view, makes it easy to modify the label space of annotations by changing the question templates."
There's tons of low hanging fruit on making interfaces that leverage human judgement at ever higher scales. I see systems like Spike and QA-SRL as infrastructure for raiding the orchid.
Who is going to develop the first Software 2.0 IDEs, which help with all of the workflows in accumulating, visualizing, cleaning, labeling, and sourcing datasets? Perhaps the IDE bubbles up images that the network suspects are mislabeled based on the per-example loss, or assists in labeling by seeding labels with predictions, or suggests useful examples to label based on the uncertainty of the network’s predictions.
Similarly, Github is a very successful home for Software 1.0 code. Is there space for a Software 2.0 Github? In this case repositories are datasets and commits are made up of additions and edits of the labels.
From Software 2.0
*Half-baked idea: Create annotation interfaces for batch annotation of scoped text fragments or the simplified annotation rules themselves. This batch-labeling-after-clustering works ok for some image datasets, but what about trying something like a human-optimized text fragment 3D projection scheme, so that someone can rapidly spot mis-labeled or mis-clustered data?
This was a small glimpse of a rapidly changing infrastructure.
A few thought exercises: Let's take having a graph of high fidelity relations from scientific text as a given... what can we build? How can we assemble some statements directly into dynamic, executable models? Can we quantify research novelty? Can we find critical gaps in understanding or emerging fields of research? What are the new interface primitives for cross-domain "graph-surfing" and other forms of hyperresearch?
Footnotes
* If there's a sciNLP epicenter it's the AllenAI institute. Besides the AllenNLP library, they constantly release open source software and research like Spike, SciFact, SciBert, SciParse, SciTail and the S2ORC corpus.
** whereby patterns get embedded into models; model parameters discretized back into patterns; patterns serialized into data; and the symbolic gets excavated from a post-symbolic avalanche
***Predicting exactly the right syntax tree (dependencies) is not as accurate as reported. This makes a lot of Dependency Pattern Matching brittle and low recall: the current effective LAS is between 50-60%. What's the effect? A good pattern only matches half the sentences it could extract from. I had this problem in a recent experiment: patterns don't work if the tree you're matching on is mislabelled. It made me less optimistic about doing all relation extraction with linguistic patterns. Thanks for Mark Neumann for making this clear:
Another less commonly discussed problem with dependency parsing is how they are evaluated. Labeled and Unlabeled Attachment Score measure the accuracy of attachment decisions in a dependency tree (with labeled additionally considering the label of the dependency arc). It has always struck me as quite bizarre why this evaluation is accepted in the research community, given the standards of evaluation in other common NLP tasks such as NER.
**** On of my favorite ideas of clustering dependency paths and then labeling the clusters in respect to some theme (like inhibition, mutation, up-regulation).
In this paper, we apply the same algorithm to cluster textual descriptions into classes, grouping descriptions of chemical-gene, gene–gene, gene-phenotype and chemical-phenotype relationships into ‘themes’.
We then map thousands of natural language descriptions to one or more of these themes, including a quantitative score that represents the strength of the mapping.
The result is a labeled, weighted network of biomedical relationships
New dependency paths are then labeled from a theme by what cluster is closest in the space. Another move from linguistics towards vector calculus